
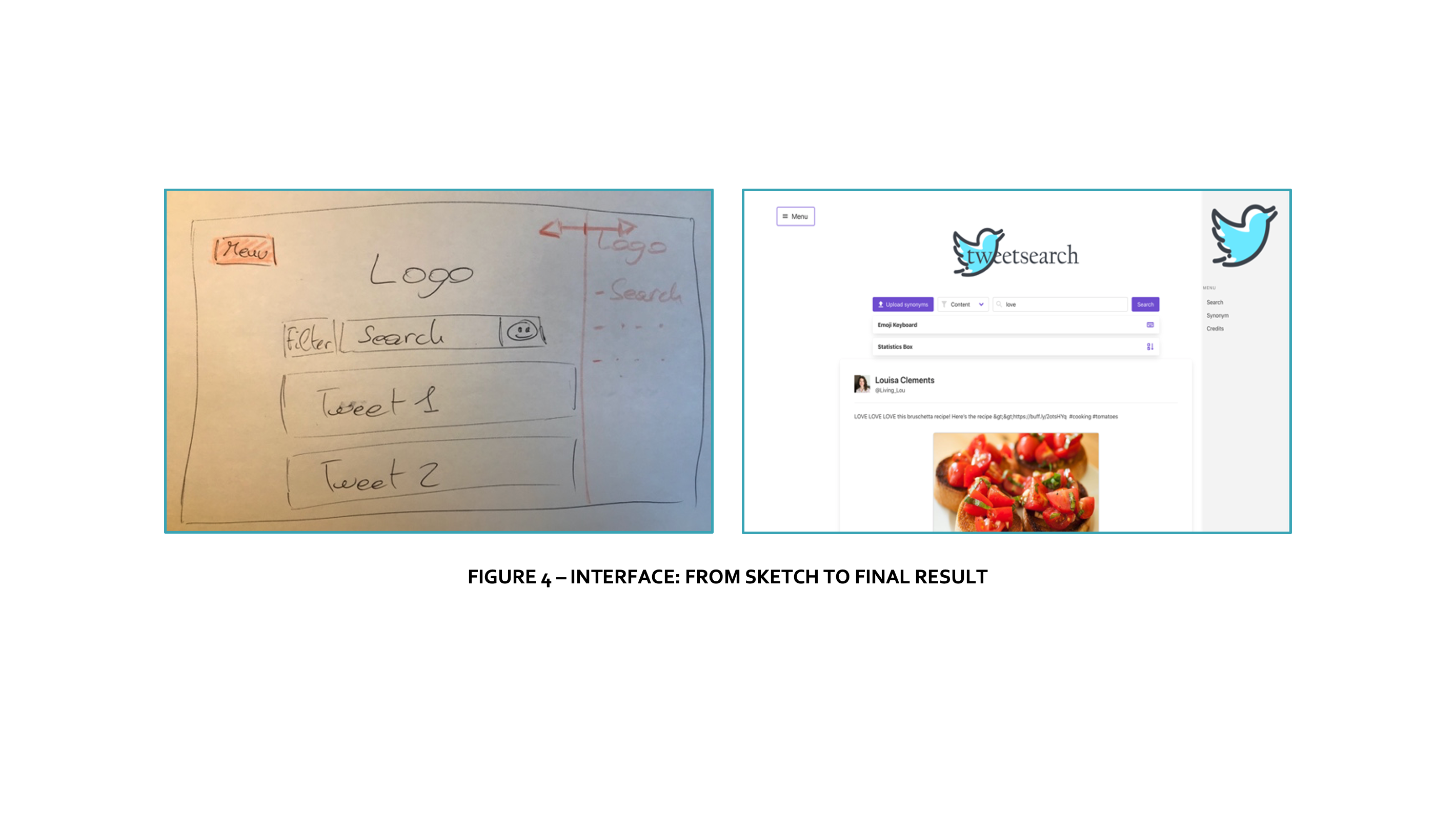

During the fifth semester of university (USI), for the Information Retrieval course, I was asked to implement a Twitter-based search engine.
This search engine, which I later developed, had to have certain characteristics: to support both normal search and emoji search. Furthermore, the query that is provided to the system can be expanded: the user can define a series of synonyms, which will then be used to expand the query.
To get a database of tweets on which to build the search engine, I built a crawler for Twitter using Scrapy, a Python framework. The crawler allowed me to collect about 10'000 tweets, which I then cataloged according to the criteria I selected.
I then indexed the tweets using Solr, which is in fact often used to implement search systems.
The user interface (frontend) was built using Vue.js, a Javascript framework.